¿Cómo debe ser un buen diseño? ¿Cómo debemos elegir qué combinaciones de atributos-niveles mostramos a cada respondiente en cada pregunta? Necesitamos saber qué hace bueno un diseño. Veremos tres criterios: balance, ortogonalidad y equilibrio posicional. Y veremos cómo combinar estos criterios para obtener una medida objetiva de bondad que nos permita comparar diseños y seleccionar el mejor posible.
Balance
Un diseño está balanceado cuando los diferentes niveles de cada atributo se muestran el mismo número de veces. En un estudio Conjoint sobre coches en el que hubiésemos definido un atributo color con los niveles rojo, blanco y negro, significaría que el total de participantes verían tantos coches de color rojo, como blancos y negros.
Queremos diseños balanceados, o al menos, lo más balanceados posibles. Cada vez que mostramos un producto con un nivel concreto de un atributo, estamos obteniendo información de ese nivel. Si mostramos los niveles un número similar de veces, aseguramos que estamos obteniendo una cantidad de información pareja de todos los niveles. Si no lo hacemos así, estaremos estimando la utilidad de unos niveles de forma muy precisa y otros de forma muy imprecisa.
Ortogonalidad
Un diseño es ortogonal cuando la cantidad de veces que un nivel de un atributo es comparado con los todos los niveles del resto de atributos es igual o proporcional. Así, en el ejemplo de los coches, si tenemos un atributo color con 3 niveles (rojo, blanco y negro) y un atributo potencia con dos niveles (80CV, 120CV), nos gustaría que los productos mostrados durante el experimento incluyan el mismo número de veces las combinaciones siguientes:
Rojo – 80CV
Rojo – 120CV
Blanco – 80CV
Blanco – 120CV
Negro – 80CV
Negro – 120CV
El criterio de ortogonalidad asegura que no confundimos atributos cuando calculamos las utilidades. Mantener la proporcionalidad en las combinaciones evita la correlación entre atributos. En nuestro ejemplo, si siempre que mostramos el color negro lo hacemos junto a la potencia 80CV, cuando un participante escoja un producto con esos atributos, ¿cómo vamos a saber si lo ha escogido por el color o por la potencia?
Queremos por lo tanto diseños lo más ortogonales posibles.
Equilibrio posicional
Durante el experimento mostraremos unos productos (cada uno con su combinación de niveles de los diferentes atributos) y pediremos al respondiente que nos diga su opción preferida. En ocasiones, la respuesta del participante puede verse afectada por el orden en que le mostramos las cosas. Por ejemplo, las opciones mostradas en primera posición suelen recibir más atención del participante y son seleccionadas con más frecuencia. Es el conocido “sesgo de orden” que afecta a cualquier pregunta de una encuesta con opciones de respuesta.
En el caso de Conjoint, queremos evitar que un nivel de un atributo aparezca más veces en primera posición que otro. Lo ideal es que todos los niveles aparezcan en las diferentes posiciones un número similar de veces. Esto se conoce como equilibrio posicional.
El equilibrio posicional tiene un impacto en el análisis de utilidades menor que los otros dos criterios, por lo que suele recibir menor atención. De hecho, es habitual no incluir en el diseño las posiciones exactas en que aparecerán los atributos-niveles, y dejar que sea el propio software de encuestas el que se ocupe de mostrar en orden aleatorio las alternativas. Este nivel de aleatoriedad es suficiente para evitar el sesgo de orden.
Eficiencia
No siempre es posible obtener un diseño perfectamente balanceado y ortogonal. Dependiendo del número de atributos, niveles por atributo, sets por respondiente y alternativas por set, puede no existir ningún diseño perfecto. Pero igualmente querremos obtener el mejor diseño posible: lo más balanceado y ortogonal posible.
Para poder buscar el mejor diseño necesitamos una medida, un número que nos diga si un diseño es mejor que otro. Esa medida existe, y se conoce como eficiencia. Un diseño eficiente obtiene mejores datos y permite calcular con mayor precisión las utilidades de los atributos.
Existen varias formas de calcular la eficiencia. Se trata de un cálculo matemático – bastante complejo - que desarrollamos al final de este post para no interferir con la explicación. Tan sólo te apuntamos aquí una idea intuitiva de cómo se calcula:
- Se calcula una matriz que describe el diseño, es decir, qué atributos-niveles se están mostrando y cómo se han combinado.
- Se calcula la matriz de información del diseño. Esta matriz nos indica con qué frecuencia se está repitiendo una combinación de niveles.
- Calculamos una medida de dispersión de los valores de la matriz. Queremos que el diseño que muestre todos las combinaciones un número similar de veces.
Existen diferentes medidas de eficiencia. La más popular es la eficiencia-D. Esta eficiencia-D puede normalizarse respecto a un diseño ideal (perfectamente balanceado y ortogonal), de forma que si estamos cerca de esta perfección, la eficiencia-D normalizada estará próxima al 100%. Por el contrario, si la eficiencia-D resulta 0%, significará que la utilidad de algún nivel de un atributo no puede calcularse debido a que se confunde con otro nivel.
Representación de un diseño
Para finalizar este post, te explicamos cómo se suele representar un diseño. Esta representación nos será de utilidad tanto para programar el cuestionario online como para calcular la eficiencia del diseño, como explicamos en el anexo de este post.
La forma habitual de representar un diseño es en forma matricial. Esta matriz:
- Tiene tantas filas como productos se muestran en el diseño.
- Tiene tantas columnas como atributos tienen los productos, más algunas otras columnas que nos indican la posición que cada producto ocupa en el experimento.
Veamos con un ejemplo cómo sería esta matriz. Imaginemos nuevamente nuestro estudio Conjoint sobre coches. Pensemos en un diseño que tiene 2 versiones, 3 sets por respondiente y 3 alternativas por set. El diseño que queremos hacer tendrá un total de 18 productos: 2 versiones x 3 sets x 3 productos en cada set.
Imaginemos que este estudio Conjoint emplea 3 atributos:
- color (rojo=1, blanco=2, negro=3)
- marca (VW=1, Renault=2, Seat=3)
- precio (10.000$=1, 15.000$=2, 20.000$=3).
Si observas la lista de atributos anterior hemos asignado un código a cada nivel de cada atributo. El rojo tiene el código 1, el blanco el 2, etc. Usando estos códigos, podemos decir que un producto consistente en un coche rojo, Renault y de 15.000$, puede codificarse como 1 2 2. La primera posición de este vector indica el color, la segunda la marca y la tercera el precio.
Usando esta nomenclatura, podemos expresar un diseño con una matriz. Simplemente ponemos los productos en filas, y transformamos los atributos en los códigos correspondientes. Por ejemplo:
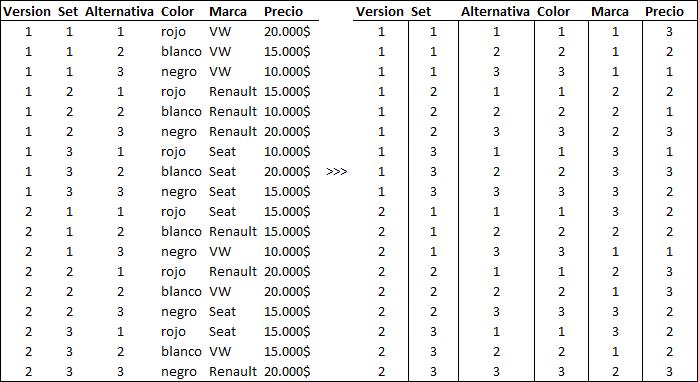
Ya tenemos una matriz numérica que describe el diseño. Toda la información del experimento está aquí. Observa que hemos añadido 3 columnas a la matriz. Esas 3 columnas indican para cada producto a que versión del diseño pertenece, en cuál de los 3 sets aparecerá y qué posición ocupa dentro de cada set.
En el próximo post te explicaremos cómo puede usarse esta medida de eficiencia para buscar buenos algoritmos. Te esperamos.
Anexo: Sólo para los matemáticos…
Si te interesan las matemáticas, te adjuntamos aquí una pequeña explicación de cómo calcular la eficiencia de un diseño. Este contenido no es necesario para comprender todos los posts que vienen a partir de ahora.
El punto de partida es la matriz que describe el diseño y que hemos visto en este mismo post. Para el cálculo de eficiencia, prescindimos de las columnas que indican versión, set y alternativa, y nos quedaremos con una matriz simple que sólo contiene los productos. Llamaremos X a esta matriz. Por ejemplo:
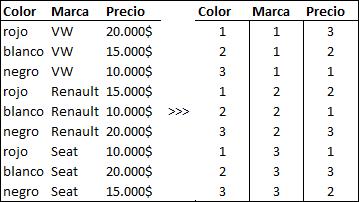
Por ejemplo, podemos usar una columna diferente para cada nivel de cada atributo. Un valor 1 en una columna indica que el nivel correspondiente está presente y un valor 0 indica que no lo está. Según esta codificación, cada columna de nuestra matriz daría lugar a 3 columnas.
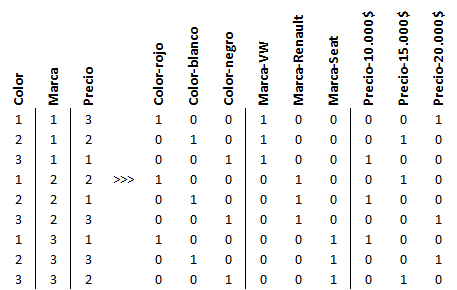
Calculemos ahora la siguiente expresión: X’X. Esta expresión, la traspuesta de la matriz que contiene el diseño por la propia matriz, se conoce como matriz de información (information matrix). Y, efectivamente, contiene mucha información.

Esta matriz simétrica contiene toda la información relativa a qué combinaciones de niveles están presentes en el diseño. Tiene un número de filas/columnas igual a la suma de niveles de los atributos. Y cada fila/columna tiene información del nivel correspondiente. Nos referiremos a una celda concreta de esta matriz usando un par de números (i,j), donde i es la fila y j la columna.
Veamos con ejemplos qué información contiene la matriz. Si queremos ver cómo se está combinando el nivel “color=negro” con el “precio=20.000$”, debemos tener en cuenta que el color negro ocupa la posición 3 dentro de los niveles y el precio 20.000$ la posición 9. Mirando la celda (3,9) – o la (9,3), ya que son iguales - veremos que aparece un valor 1. Significa que en el experimento sólo aparece una vez un coche de color negro a 20.000$. Podemos ver que es correcto: el 6º producto mostrado en el diseño es el 3 2 3, que corresponde a un coche negro, Renault a 20.000$.
Observa que la diagonal de la matriz de información está ocupada por el valor 3. ¿Qué significa esto? La diagonal recoge las veces que un nivel de un atributo se combina consigo mismo, lo que es equivalente a decir que recoge las veces que aparece un atributo. Por ejemplo, si miramos la celda (4,4), el número que encontramos (3) son las veces que la marca VW aparece en el diseño. Mirando directamente el diseño vemos que es cierto, la marca VW aparece en los productos 1,2 y 3.
Observa también que en la matriz de información aparecen algunos ceros. Por ejemplo, la celda (1,2). En este caso, es normal, ya que el atributo en primera posición es el color rojo y en segunda es el color blanco. No puede existir un coche rojo y blanco a la vez. Es por esa razón que en las submatrices que corresponden a los niveles de un mismo atributo, los elementos fuera de la diagonal tienen siempre valor 0. El siguiente diagrama verás ilustrado lo explicado anteriormente

El diseño que hemos tomado como ejemplo es francamente bueno. Observa que combina todos los niveles de atributos combinables y lo hace el mismo número de veces. Veamos un ejemplo del efecto que tiene alterar alguno de los productos del diseño original, en concreto, vamos a cambiar el color del primer producto de rojo (1) a blanco (2). Es decir, cambiamos el producto 1 1 3 por el 2 2 3.Si lo hacemos, calculamos la matriz del diseño y evaluamos la matriz de información, resulta lo siguiente.

Observa que las filas (y las columnas) alteradas son la primera y la segunda, ya que hemos suprimido un producto con nivel 1 y lo hemos reemplazado por otro con nivel 2. Observa también que la celda (1,1) ha pasado de 3 a 2, y la (2,2) de 3 a 4. También se han producido otras afectaciones. Por ejemplo, la celda (1,9) tiene un 0, indicando que este diseño no combina ni una sola vez el color negro con el precio 20.000$.
Obviamente, este diseño es peor que el anterior. La eficiencia justamente es la medida que nos dice qué matriz de información es mejor. Resulta que la matriz de varianza-covarianza de las utilidades que queremos estimar mediante el Conjoint es proporcional a la inversa de esta matriz de información, es decir, a (X’X)-1.. En concreto, es σ2(X’X)-1, donde σ2 es una constante desconocida que depende de los datos que obtengamos en el experimento.
Por lo tanto, la precisión que obtendremos en nuestras estimaciones dependerá de la dispersión de opiniones que resulten de las respuestas pero también del diseño que empleemos. Y para que el diseño añada la menor desviación posible, queremos minimizar (X’X)-1.
(X’X)-1 es una matriz, no un valor. Tenemos una herramienta matemática que nos permite transformar una matriz, vista como un conjunto de puntos, en unas cantidades que expresan lo grande que es (el espacio que ocupan sus puntos). Estas cantidades son los valores propios de una matriz. Si estos valores son grandes, la matriz es grande. El promedio de los valores propios es por lo tanto una medida resumida del tamaño de la matriz y podemos emplearla para medir la eficiencia del diseño. Queremos un promedio de valores propios pequeño.
En función del tipo de promedio que hacemos de los valores propios, estaremos hablando de diferentes tipos de eficiencia:
- Eficiencia-A: Promedio aritmético de valores propios. Se suman valores y se divide por el número de valores.
- Eficiencia-D: Promedio geométrico de valores propios. Se multiplican valores y se hace la raíz n-ésima.
Por diversas razones, la Eficiencia-D es la que tiene mejores propiedades. Teniendo en cuenta que el producto de valores propios es igual al determinante de la matriz, esta media geométrica de valores propios podemos expresarla de la siguiente manera
Diseño eficiente : |(X’X)<sup>-1</sup>|<sup>1/p</sup> mínimo
donde p es la cantidad de utilidades a estimar. Por lo tanto, podemos definir una medida de eficiencia como
Eficiencia-D : 1 / |(X’X)<sup>-1</sup>|<sup>1/p</sup>
Esta medida cumple la función básica que necesitamos. Si un diseño es mejor que otro, tiene Eficiencia-D mayor.
Algunas consideraciones finales:
- El cálculo de eficiencia que hemos explicado es para un diseño Conjoint general, no para uno basado en elección. Para el caso que nos interesa, es necesario hace una simple manipulación de las filas de la matriz de diseño X. En concreto, restar a cada fila todas las otras filas presentes en el mismo set multiplicadas dividas por el tamaño del set. De esta forma, la matriz X también contiene información de cómo se combinan los atributos dentro de un mismo set.
- Podemos usar formas de codificación alternativas, más adecuadas para calcular la eficiencia. Por ejemplo, en un atributo con 3 niveles, como el color de nuestro ejemplo, en realidad sólo hay 2 niveles independientes. Si el color no es rojo ni blanco, seguro que es negro. Eso nos permite hacer que la matriz de diseño tenga un número de columnas igual al número de utilidades realmente independientes, que es igual a la suma de todos los niveles menos el número de atributos (en nuestro ejemplo 9-3=6).
- Si la codificación que empleamos, además, es de tipo “ortogonal estandarizada”, un diseño perfectamente balanceado y ortogonal tendrá una eficiencia igual al número de productos incluidos en el diseño. Denominaremos como N esta cantidad. Esto nos permite saber cuál es la máxima eficiencia que podemos obtener. Si dividimos la eficiencia por esta eficiencia máxima que podemos obtener (N) y multiplicamos por 100, tendremos una medida de eficiencia normalizada.

- Si el diseño es mejor, la eficiencia-D es mayor.
- Si el diseño es óptimo la eficiencia-D es 100%.
- Si alguna utilidad no se puede estimar (porque correlaciona totalmente con otra), la eficiencia-D es 0%.

¿Te ha gustado el post? ¿Quieres profundizar más sobre el tema? Pues hemos preparado una serie de diez cápsulas sobre Conjoint. ¡No te pierdas ninguna!
ÍNDICE: Serie Cápsulas sobre Conjoint
Cápsula 1: Qué es un estudio Conjoint y cómo utilizarlo
Cápsula 2: Entendiendo el concepto de utilidad
Cápsula 3: Fases de un Conjoint
Cápsula 4: Diseño experimental, parámetros de diseño
Cápsula 5: Diseño experimental, calidad de un diseño
Cápsula 6: Diseño experimental y estrategias para encontrar un buen diseño
Cápsula 7: Programación de cuestionarios Conjoint
Cápsula 8 - Análisis agregado de un Conjoint