

Es probable que el término «datos de comportamiento» y sus ventajas para la investigación de mercados sean desconocidos para la mayoría de lectores. Una de las características destacadas de este tipo de información es que los datos recolectados son independientes de la memoria y la deseabilidad social de nuestros participantes, por lo que prevalecen ante los datos declarativos cuando se necesita una perspectiva más objetiva. Más concretamente, hoy en día son muy populares los datos de comportamiento online debido al amplio abanico de posibilidades que ofrecen.
Estaremos de acuerdo en que analizar los dominios que visitamos en Internet, el orden de visita y qué hacemos en cada dominio puede constituir información muy valiosa para la investigación de mercados. Hay cientos de artículos y vídeos en línea explicando la importancia de este tipo de datos y qué se puede hacer con ellos. Sin embargo, la gran mayoría solo abordan el tema de forma superficial, sin entrar en detalles ni en la parte más técnica. Luego, aunque tengamos un objetivo claro, puede que no sepamos cómo usar nuestros datos de forma explícita para dar respuesta a las preguntas que necesitamos responder.
Este artículo pretende esquematizar un simple análisis que va desde un puñado de datos de comportamiento online, hasta una serie de conclusiones que nos servirán para tomar decisiones informadas. A modo de ejemplo, usaremos los datos recolectados de las visitas a sitios web relacionados con museos. A partir de este conjunto de datos, sabremos qué sitios web reciben más visitas, el perfil de los visitantes, quién ha comprado entradas en línea y el perfil de estos compradores. Los resultados del análisis pueden ser determinantes a la hora de lanzar una campaña de marketing, ya que nos permitirán hacer una segregación en función de los intereses de cada grupo.
Y ahora seguramente te preguntarás de dónde sacamos estos datos. Netquest es una empresa de investigación de mercados que no se limita a enviar encuestas a sus panelistas, sino que hace una medición pasiva del comportamiento de aquellos panelistas invitados que hayan dado su consentimiento explícito. Los panelistas tan solo tienen que instalar el tracker en los dispositivos de su elección y este nos comunicará la actividad digital del usuario desde el dispositivo en cuestión. Para los fines perseguidos por este artículo, hemos recolectado todos los registros asociados a museoreinasofia.es (Museo Reina Sofía en Madrid), sagradafamilia.org (Sagrada Familia en Barcelona), patrimonionacional.es (Patrimonio Nacional de España) y cac.es (Ciutat de les Arts i les Ciències en Valencia). Estos datos provienen del panel de España en 2017, formado por 11.088 observaciones y con la participación de 722 panelistas. El análisis y los escenarios se desarrollaron en R. Antes de adentrarnos en el análisis, es preciso describir con más detalle la serie de datos.
Datos usados de comportamiento digital
Cada vez que los panelistas cargan una página web, un conjunto de variables identifican de forma unívoca esta visita entre todo el bloque de comportamiento digital. Los datos deben incluir necesariamente la URL de acceso, la marca de tiempo, el dispositivo empleado y la persona que ha realizado el acceso. Se podría pensar que esta información es suficiente para determinar cualquier visita web. Sin embargo, en pos de la simplicidad del análisis, hemos añadido el nombre de dominio de la URL. Esta variable nos dirá fácilmente si un panelista navega en un mismo dominio, o si pasa de un dominio a otro, sin tener que manipular la URL.

Primer dato relevante: contar las visitas
La variable del nombre de dominio nos sugiere el primer análisis: podemos agrupar las visitas a un mismo dominio y contar cuántas vemos en cada grupo. Esto nos dirá cuántas veces se ha visitado cada una de las páginas web. Si, además, clasificamos estos datos, podremos establecer rankings de popularidad de todos los dominios considerados.
Aplicado a nuestros datos sobre museos, agrupados por nombre de dominio, veamos cuáles son los resultados:
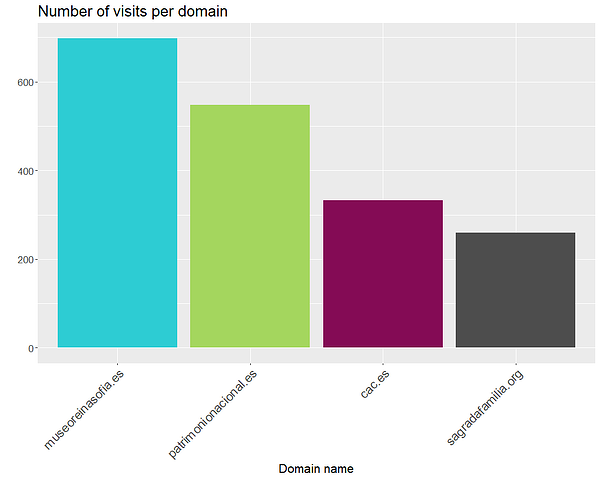
Se aprecia claramente que el museo con un mayor número de visitas es el Reina Sofía. Una posible explicación es que este museo cambia su exposición artística periódicamente, alentando así a los visitantes a consultar su página web con frecuencia para ver las novedades.
Con este tipo de análisis sabremos la popularidad relativa de nuestra página web respecto a las demás en el mismo ámbito. Para ello, la lista de dominios debería incluir nuestra página web y la de nuestros competidores directos, de manera que el ranking final nos indique el grado de popularidad en comparación con las demás.
¿Quiénes son los visitantes?
Una pregunta habitual es quién visita los sitios web que queremos analizar. Disponer de esta información nos permitirá:
- Conocer los usuarios de cada sitio web, y usar esta información para mejorar la retención
- Encontrar discrepancias entre nuestra población objetivo esperada y el público real, de modo que podamos lanzar campañas de marketing enfocadas a esos grupos específicos
- Encontrar nuevos usuarios potenciales entre aquellos que visiten sitios web parecidos al nuestro
La idea detrás del análisis es volver a clasificar por nombre de dominio y agregar la información sociodemográfica de la gente que accede a cada dominio; con esto, tendremos un perfil de sus visitantes. Nuestros datos no incluyen esta información, pero sí tenemos una variable que almacena quién ha llevado a cabo cada una de las visitas: el identificador del panelista. Por otra parte, dado que los visitantes son panelistas de Netquest, disponemos de una gran cantidad de datos de perfil que podemos usar, y están asociados a un identificador de panelista. A continuación, solo tenemos que relacionar los identificadores de panelistas y añadir sus datos de perfil a nuestros datos originales. Por consiguiente, cada observación en el conjunto de datos resultantes incluirá la URL a la que se ha accedido, la fecha y la hora, el dispositivo empleado, el nombre de dominio y la persona que ha realizado la visita, además de todos los datos que necesitamos para conformar el perfil de los usuarios. A partir de ahí, podremos clasificar los datos agrupándolos por nombre de dominio y obtener porcentajes para cada uno de los rasgos de los usuarios. Así habremos creado un perfil de los usuarios de cada dominio con muy poco esfuerzo.
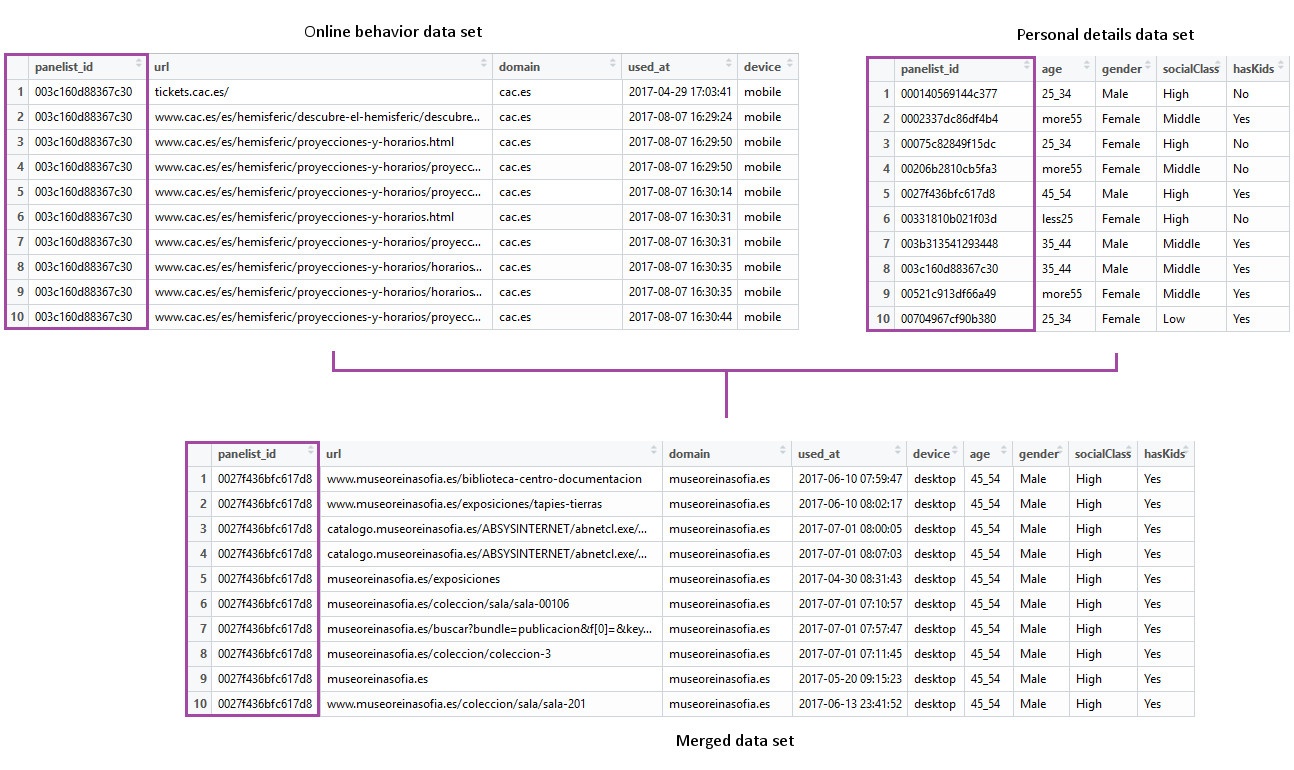
Ahora vamos a realizar la fusión con nuestro conjunto de datos de museos. Para obtener el perfil del visitante, solo incluiremos las variables de género, clase social, número de hijos y si leen la prensa o no. Después, agruparemos por nombre de dominio y calcularemos los porcentajes de cada posible valor en las variables incluidas. Por ejemplo, en el caso de la variable de género, calcularemos el porcentaje de mujeres y hombres. Haremos lo mismo para el resto de variables.
Veamos los resultados:
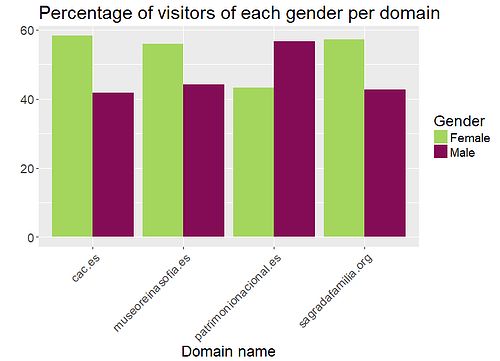
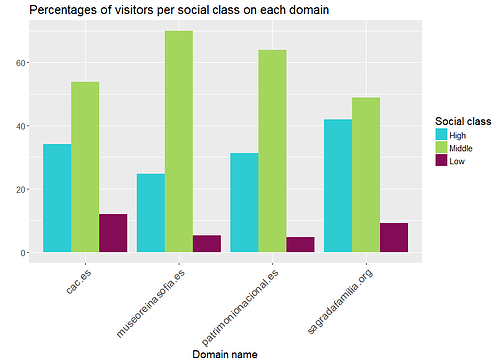
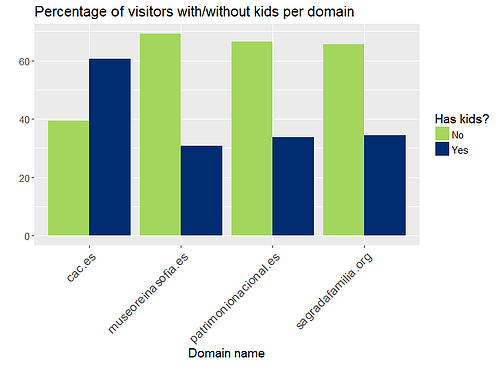
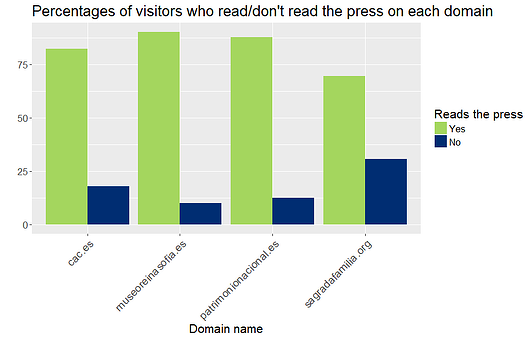
No se observan diferencias críticas en el porcentaje de hombres y mujeres que han visitado los sitios web. No obstante, sí hemos detectado divergencias en otras tres variables. La clase social nos indica claramente que la clase media visita los sitios web considerados con mayor frecuencia que las clases alta y baja. La variable relativa a los hijos nos dice que la Ciutat de les Arts i les Ciències es una opción más adecuada para niños que las otras tres. Por último, la mayoría de visitantes de sitios web relacionados con museos lee la prensa.
De forma intuitiva, podemos pensar que añadir información sobre los visitantes es la única manera de obtener su perfil. Sin embargo, los propios datos de comportamiento digital nos pueden revelar los hábitos de los usuarios. Si segmentamos la variable de día y hora en distintas franjas (por ejemplo, madrugada, mañana, tarde y noche) y agregamos los datos por dominio, sabremos cuándo suelen visitar los usuarios estos sitios web. Se puede aplicar el mismo procedimiento para saber el mes en que se visitan los sitios web de los museos que, a su vez, nos puede servir para descifrar su comportamiento anual. A partir de ahí, podremos determinar si estamos ante un comportamiento periódico o si cambia cada año. Además, si disponemos de datos históricos, estos nos podrían ayudar a detectar posibles problemas técnicos debidos a caídas drásticas en el número de visitas.
En nuestro ejemplo, hemos generado una nueva variable: la franja horaria. Hemos decidido dividir la información de día y hora en cuatro períodos distintos: madrugada (00:00 h-06:00 h), mañana (06:00 h-12:00 h), tarde (12:00 h-18:00 h) y noche (18:00 h-00:00 h). Una vez agrupados los datos por dominio y tras agregarlos en porcentajes, hemos obtenido los siguientes resultados:
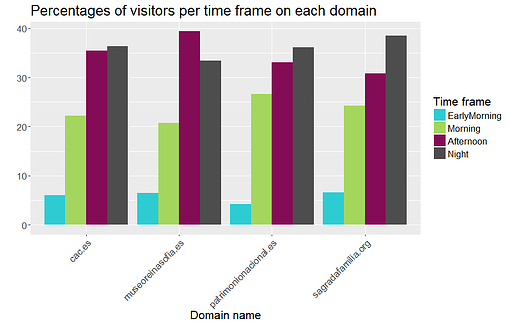
Tal y como se aprecia, la mayoría de usuarios acceden a estos sitios web por la tarde o por la noche, mientras que pocos lo hacen por la mañana.
¿Los visitantes realizan compras en estos sitios web?
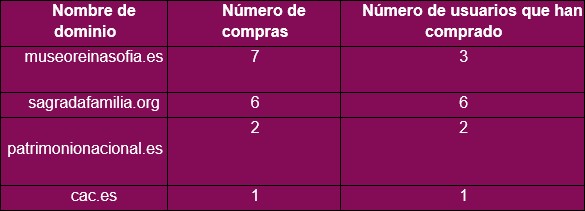
También nos podríamos preguntar si los usuarios han comprado algo durante su visita a los sitios web y, en caso afirmativo, cómo podemos describirles como compradores digitales. Sin embargo, detectar las compras web en este conjunto de datos no es tan sencillo. Tenemos que saber de antemano la URL de la confirmación de compra, que o bien nos la puede proporcionar el cliente, o bien la tendremos que encontrar por nuestra cuenta, cosa que puede resultar una tarea engorrosa. Pero, una vez la tenemos, podemos detectar las URL de compra con expresiones regulares y marcar todas las observaciones que hagamos. Si agrupamos el total de visitas y contamos cuántas hay por dominio, obtendremos el total de compras por sitio web. Precisamente eso fue lo que hicimos con nuestra serie de datos de ejemplo. A continuación, se muestra la tabla que resume el número de compras y el número de usuarios por dominio:
Por último, podemos elaborar un perfil de los compradores incluyendo los datos de perfil que hemos utilizado anteriormente, agregándolos por nombre de dominio siguiendo el mismo procedimiento. Hemos generado perfiles sencillos con las variables «edad» y «franja horaria»:
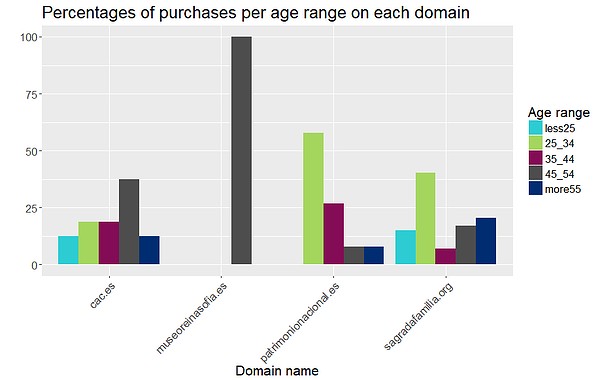
Los compradores de los sitios web patrimonionacional.es y sagradafamilia.org tienen mayor probabilidad de estar en el rango de edad [25, 34]. Los del dominio museoreinasofia.es se encuentran en la franja [45, 55], mientras que los del cac.es se enmarcan en distintas franjas de edad. En cuanto a las franjas horarias en las que se realizaron las compras, se aprecia que el horario preferido para comprar es por la noche y por la tarde. A pesar de que la mitad de las compras realizadas en cac.es se produjeron de madrugada, parece que es más bien una prolongación de la franja nocturna. Estamos, pues, ante un resultado coherente con el análisis previo, donde vimos que los usuarios prefieren visitar estos sitios web por la tarde o por la noche.
Conclusiones y sugerencias para análisis adicionales
El análisis descrito en este artículo es extremadamente sencillo porque consiste solamente en agrupar los datos por nombre de dominio y luego agregarlos para obtener una descripción de las visitas y compras web, así como de los usuarios de cada dominio. Sin embargo, a pesar de su sencillez, nos ha proporcionado mucha información valiosa que podemos utilizar para tomar varias decisiones informadas.
Con un análisis más complejo de los mismos datos podríamos obtener otros tipos de información. Veamos algunas de las posibilidades, con sus usos potenciales:
- Agrupar los visitantes por sitios web específicos: segmentar la población objetivo nos permitirá lanzar campañas dirigidas a nuestro público objetivo dividido en grupos. La segmentación se puede hacer aplicando cualquier criterio: datos sociodemográficos, motivos por los que se visita el sitio web, intereses personales, etc.
- Predicción de las compras: un modelo predictivo que indica en qué momento los usuarios son más propensos a comprar productos específicos nos ayudará a organizar el sitio web
- Calcular la probabilidad de crear nuevos usuarios: descubrir a los usuarios potenciales con la mayor probabilidad de convertirse en nuevos usuarios se puede traducir en un ahorro importante de costes
- Sistemas de recomendación: sugerirá los productos que los usuarios se plantean adquirir, incrementando así el volumen total de compras digitales.



